Software Measures
In the following, a selection of protection measures which increase the privacy or integrity of machine learning (ML) models (e.g. neural networks) is presented.
First, the general training of neural networks is described since the protective measures are applied within the training. A neural network is a complex mathematical function that is represented by interlinked layers which consist of many parameters. A neural net learns to classify data points of a target data distribution by means of training data. Here, learning refers to the adjustment of the neural net’s internal parameters in an iterative process, the training. Therein, the neural net classifies training data, s.t. the predicted class is propagated back through the network to calculate the direction in which the parameters have to be adjusted in order to get close to the correct class. The adjustment is called gradient descent. The training is terminated when the model’s prediction quality stops improving.
Adversarial Retraining

Adversarial Retraining is a protection measure against so-called adversarial examples (AE). AEs are manipulated inputs for neural networks which aim at causing a wrong prediction. The manipulation is as subtle such that human observers can hardly recognize it as such. In adversarial retraining, AEs are integrated into the training data set of the model to protect so that its adversarial robustness and hence its integrity is improved.
One impressive example of adversarial attacks is the one pixel attack which only changes a single pixel of an image. This minor perturbation is sufficient in many cases to trick the targeted neural net s.t. it predicts a wrong class.
Functioning
An AE can be produced within an adversarial attack by altering a real data point that was classified by the target model. More precisely, the prediction is propagated back through the network up to the input data point, s.t. its direction towards a wrong prediction can be calculated. Accordingly, the input data point is perturbed just enough to be misclassified. Depending on the concrete kind of adversarial attack, this gradient descent within the data point is applied differently or repeatedly. AEs are produced within adversarial retraining and together with the training data are given to the model to train and protect.
Usage
Adversarial retraining cannot be applied to linear models like e.g. support vector machines or linear regression. In contrast, neural networks acquire a significantly improved robustness against AEs when retrained with adversarial retraining.
Differential Privacy

Differential Privacy (DP) is a popular metric that allows to measure the influence of particular data points on the result of a data processing. This is equivalent to the privacy loss of the persons to which the data belongs. The privacy loss can be limited by inducing noise into the data processing. Although DP was originally invented in the context of databases, it is applied to privacy-preserving ML in recent years.
In 2006, the streaming service Netflix announced a public competition called Netflix Prize. The goal was to find the best algorithm to predict the movie ratings of certain users. For this purpose, the streaming service provided user data from more than 500,000 users for the training of competing algorithms. Two researchers at the University of Texas developed a linkage attack that maps the published user data with movie ratings from IMDb, a movie rating platform. As a result, many Netflix users have been de-anonymized.
Functioning
In the context of ML, privacy can be protected by inserting noise into the information about training data during training of a model. More precisely, the gradient corresponding to a single data point is clipped s.t. its norm does not exceed a certain value, and the gradient is perturbed by random noise. The combination of both techniques leads to a reduced privacy loss and even enables the quantification of it.
Homomorphic Encryption

Homomorphic Encryption (HE) enables the execution of mathematical operations like addition or multiplication on encrypted data. Results are still present in an encrypted form and are visible only with knowledge of the corresponding decryption key. Note that the same results are obtained as if neither encryption nor decryption would have been applied.
Researchers work on practical applications of HE like, e.g., the improvement of security and transparency of elections. Encrypted votes could be counted automatically—and therefore correctly—by means of the Paillier crypto system for example. This would enable authenticity of elections while also protecting the privacy of voters.
Usage
HE could be used in ML to protect the privacy of persons whose data are used either for training of a model or for inference by allowing models to operate on encrypted data. Unfortunately, no such technique has been developed for neural networks so far.
Anomaly Detection

Anomaly detection comprises methods to detect unusual patterns in data. Critical inputs like AEs can be filtered out of training data by means of anomaly detection. This leads to an improved robustness and thus to the integrity of ML models.
Anomaly detection is applied in many areas like for example text and image processing, fraud detection, or medicine.
Usage
Usually, anomaly detection is applied to improve the robustness of neural networks by using a second neural network that detects and removes critical inputs. This method requires additional computing resources. As an alternative to protecting the robustness and integrity, anomaly detection can be used to improve the privacy protection of training data in ML. Thus, membership inference attacks can be used to remove highly vulnerable data from the training dataset.
Evaluation
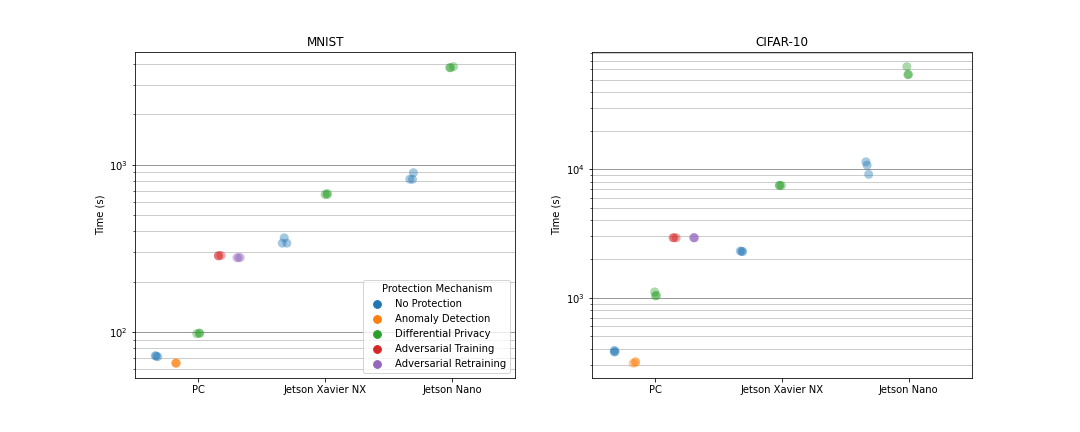
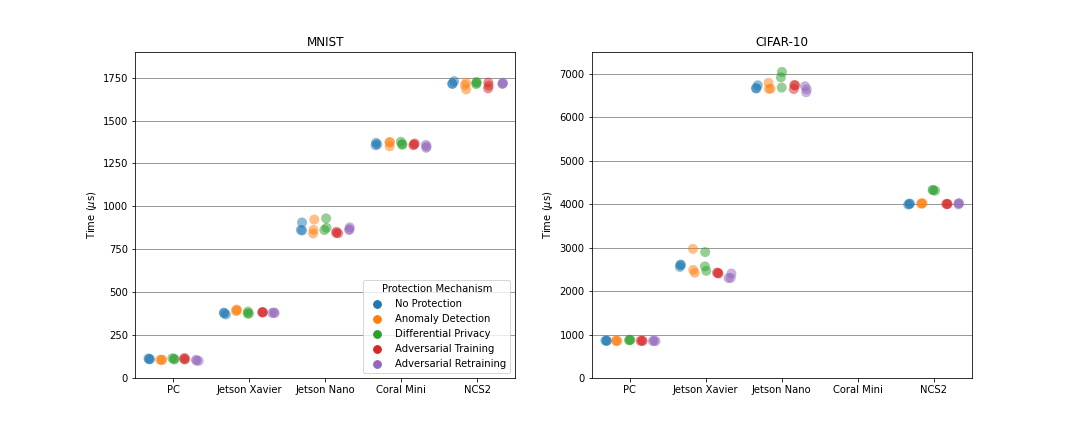
In order to compare the different protection measures and to evaluate their suitability in the context of resource constrained embedded and mobile AI, several ML experiments were conducted. Therein, neural networks were trained each with one or without any protection mechanism on the MNIST or CIFAR-10 dataset. The MNIST dataset contains 70.000 gray-scaled images of hand-written digits. In contrast, the CIFAR-10 dataset comprises 60,000 colored images of animals or vehicles. For the MNIST dataset, a multi-layer perceptron (MLP) consisting of about 670,000 adjustable parameters was used, while a convolutional neural network (CNN) was selected for the CIFAR-10 dataset that consists of approximately 5.8 mio. parameters. The models were trained over 50 epochs and afterwards deployed on different embedded devices to infer 10,000 test data points. For the inference, the most accurate version of a model over all training epochs was selected to classify the test data.
Comparison of Prediction Quality
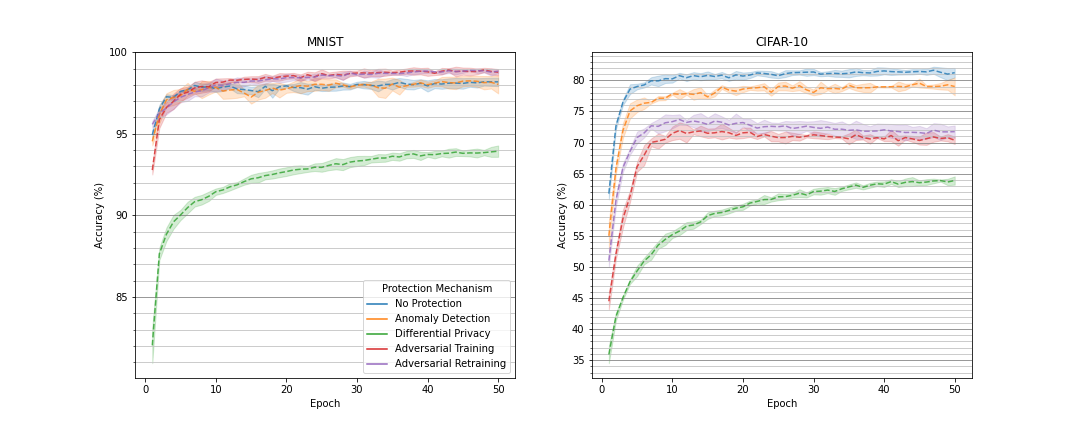
Comparison of Training Time
Comparison of Inference Time
Literaturempfehlungen
Goodfellow, I. J., Shlens, J., and Szegedy, C. “Explaining and Harnessing Adversarial Examples” in ICLR (2015).
Abadi, M., Chu, A., Goodfellow, I. J., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. “Deep Learning with Differential Privacy” in ACM CCS (2016).
Acar, A., Aksu, H., Uluagac, A. S., and Conti, M. “A Survey on Homomorphic Encryption Schemes: Theory and Implementation” in ACM CSUR (2018).
Chandola, V., Banerjee, A., and Kumar, V. “Anomaly Detection: A Survey” in ACM CSUR (2009).